USB-Technologie verstehen – Jenseits des Marketings
Kontinuierliche Analysen zu Flash-Speichern, USB-Technologie und Datensicherheit – klar erklärt für alle, die verstehen wollen, was tatsächlich im Hintergrund passiert.
Kernwissensbereiche
Flash-Speicher
Wie NAND funktioniert, Mythen uber die Lebensdauer, Performance-Verhalten und Preisentwicklungen.
USB-Sicherheit
Kopierschutz, Risiken von Datenlecks, Schreibschutz und Compliance-Realitäten.
Datenintegritaet
Testwerkzeuge, gefälschte Kapazitäten, Korruptionsprobleme und Verifizierungsmethoden.
USB-Hardware
Was steckt in einem Flash-Laufwerk, Firmware-Verhalten und Performance-Kompromisse.
Kopiersysteme
Massenkopieren, Verifizierungsmethoden und Workflow-Design.
Branchenanalyse
Marktveränderungen, Lieferengpässe, KI-Nachfrage und Dynamik der Flash-Preise.
Hervorgehobene Analyse
Tiefgründige Einblicke in reales USB-Verhalten, Ökonomie von Flash-Speichern, Controller-Entscheidungen und Sicherheits-Kompromisse.
Neueste Artikel
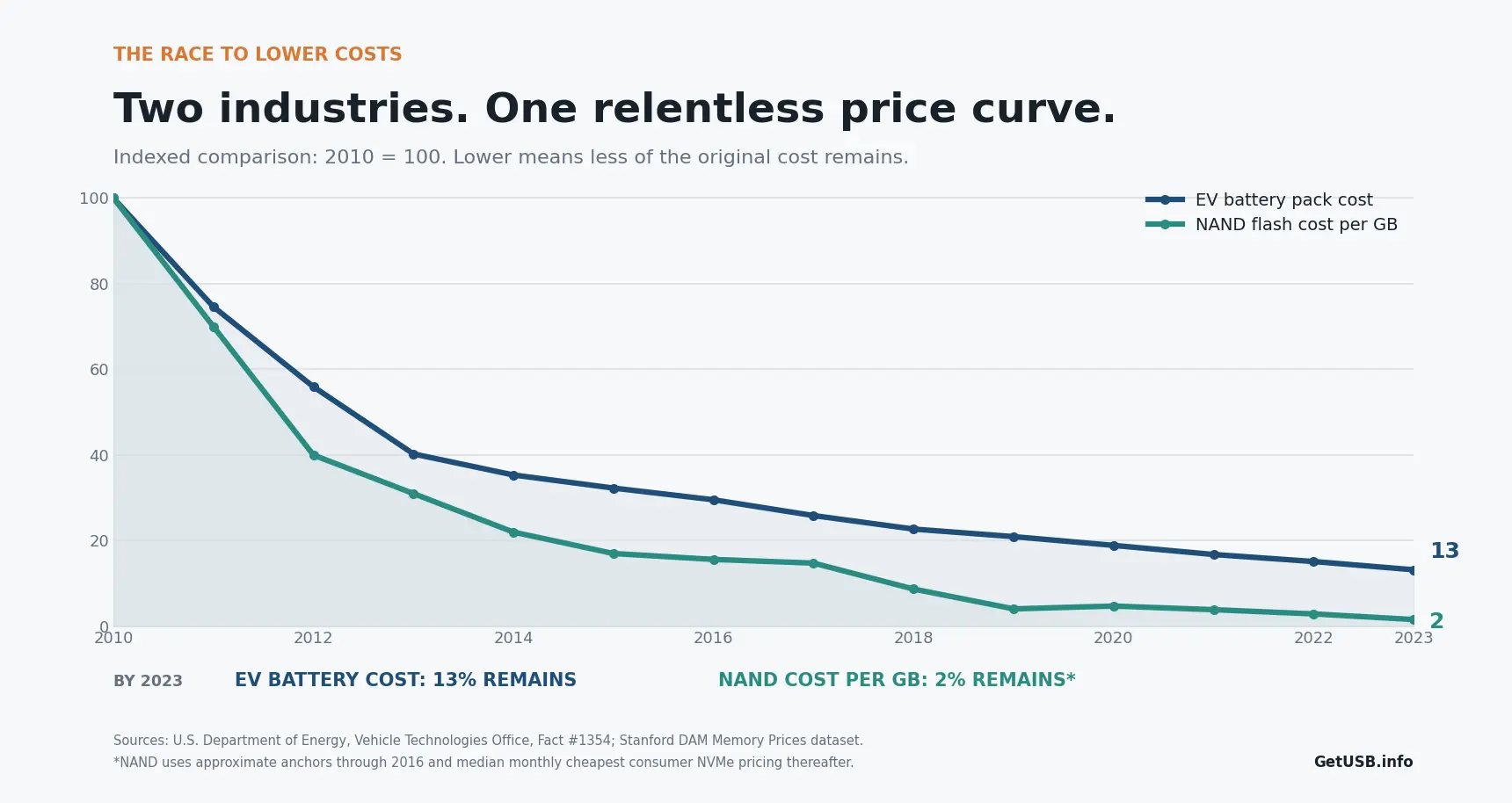
Milliarden für den Bau. Centbeträge pro Einheit

Wenn USB-Geräte mehr versprechen, als sie beweisen können
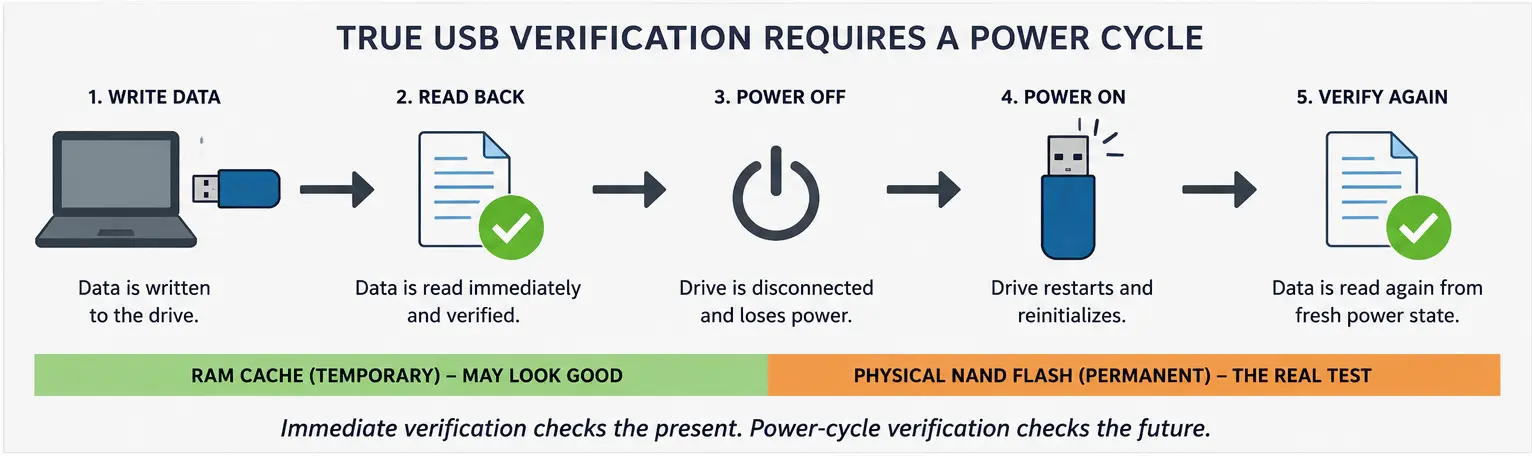
USB-Datenverifizierung erklärt: Warum ein Power-Cycle wichtig ist
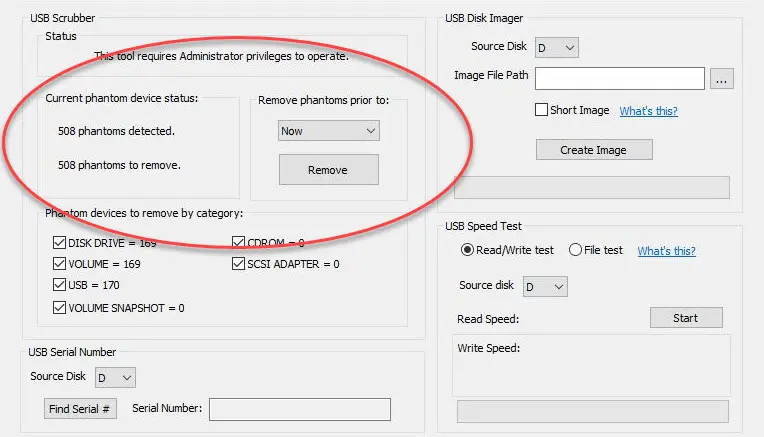
Ja, Windows speichert eine Historie jedes USB-Geräts. Genau deshalb ist das nützlich

Der größte KI-Engpass ist nicht Software. Es sind Elektriker
