
NAND verschwindet nicht, aber KI-Server sind heute auf mehr als nur Flash angewiesen
Seit mehr als zwei Jahrzehnten beobachtet GetUSB, wie sich Daten tatsächlich bewegen – nicht nur, wie sie vermarktet werden. In dieser Zeit haben wir mehrere Evolutionszyklen im Storage-Bereich erlebt: vom Rückgang mechanischer Festplatten über den Aufstieg von Flash bis hin zu heutigen Systemen, in denen Storage nicht mehr nur ein passiver Bestandteil ist, sondern ein aktiver Teil der gesamten Infrastruktur geworden ist.
Was aktuell im Bereich der KI-Infrastruktur passiert, fühlt sich wieder wie so ein Wendepunkt an – allerdings mit einer anderen Art von Druck, der diese Entwicklung antreibt.
NAND-Flash verschwindet nicht, darüber gibt es eigentlich keine Diskussion. Es ist weiterhin das Fundament moderner Speicherlösungen und erfüllt diese Aufgabe nach wie vor sehr gut. Gleichzeitig steigt die Nachfrage nach NAND rapide an – vor allem durch KI-Workloads, die enorme Datenmengen benötigen und ständig darauf zugreifen müssen. Diese Nachfrage beginnt spürbar gegen die verfügbare Versorgung zu drücken, sei es durch steigende Preise, strengere Zuteilungen oder schlicht längere Lieferzeiten bei großen Deployments.
Sobald solche Ungleichgewichte sichtbar werden, wartet die Branche nicht einfach ab, bis sich alles wieder normalisiert. Sie sucht nach alternativen Lösungen – und genau an diesem Punkt beginnt sich etwas zu verschieben.
Die Annahme, die jeder macht
Von außen betrachtet wirkt die Logik zunächst weiterhin plausibel. KI-Modelle werden größer, Datensätze wachsen kontinuierlich, und immer mehr Infrastruktur wird aufgebaut, um das alles zu unterstützen – also scheint die naheliegende Lösung zu sein, einfach mehr Storage hinzuzufügen. Mehr SSDs, mehr Kapazität, mehr Flash im Rack – und das System sollte mithalten können.
Dieser Ansatz hat lange funktioniert und tut es in vielen Umgebungen auch heute noch. Die zugrunde liegende Annahme ist jedoch, dass sich Storage unter KI-Workloads genauso verhält wie unter klassischen Anwendungen – und genau hier beginnt die Realität auseinanderzugehen.
Zusätzlich setzt dieser Ansatz voraus, dass NAND weiterhin in den benötigten Mengen und zu stabilen Preisen verfügbar ist – was mit steigender Nachfrage zunehmend unsicher wird.
Wo NAND an seine Grenzen stößt
NAND-Flash ist außergewöhnlich gut in dem, wofür es entwickelt wurde. Es bietet dichten, zuverlässigen und vergleichsweise schnellen Speicher und hat im klassischen Computing viele Probleme früherer Technologien gelöst. Auch heute funktioniert es für die meisten Workloads genau so, wie man es erwartet.
KI-Workloads verlangen jedoch etwas leicht anderes – und dieser Unterschied ist entscheidender, als es auf den ersten Blick wirkt.
Statt Daten einfach nur zu speichern und bei Bedarf abzurufen, benötigen diese Systeme einen konstanten, kontinuierlichen Datenstrom in hochgradig parallele Recheneinheiten – oft mit Geschwindigkeiten, die sich mit klassischen Storage-Architekturen nur schwer dauerhaft aufrechterhalten lassen. Hochleistungs-SSDs können Lastspitzen und große Warteschlangen gut bewältigen, aber tausende GPU-Kerne in Echtzeit zu versorgen ist eine völlig andere Herausforderung.
Gleichzeitig wird das zugrunde liegende Medium – das NAND selbst – teurer und in manchen Fällen schwieriger in großen Stückzahlen zu beschaffen. Die Branche steht also vor zwei gleichzeitigen Problemen: dem Bedarf an höherem und konstanterem Datendurchsatz und der Tatsache, dass genau das Medium, das diesen liefern soll, unter Kosten- und Lieferdruck steht.
Diese Kombination treibt den aktuellen Wandel voran. Nicht weil NAND nicht mehr funktioniert, sondern weil es allein nicht mehr ausreicht, um mit den Anforderungen moderner KI-Systeme Schritt zu halten.
Die Branche hat NAND nicht ersetzt – sie hat darum herumgebaut
Was wir derzeit in der KI-Infrastruktur sehen, ist keine klare Ablösung von NAND und auch kein abruptes Verschwinden von Flash aus dem System. Im Gegenteil: NAND ist nach wie vor ein zentraler Bestandteil. Der Unterschied liegt darin, dass es nicht mehr erwartet wird, die gesamte Last alleine zu tragen.
Stattdessen baut die Branche zusätzliche Schichten darum herum auf, von denen jede für einen bestimmten Teil der Workloads optimiert ist – Aufgaben, für die NAND allein nie wirklich gedacht war. In der Praxis bedeutet das, dass man neu darüber nachdenkt, wie Daten durch ein System fließen, wo sie sich in verschiedenen Phasen befinden und wie schnell sie verfügbar sein müssen – abhängig davon, was auf der Compute-Seite passiert.
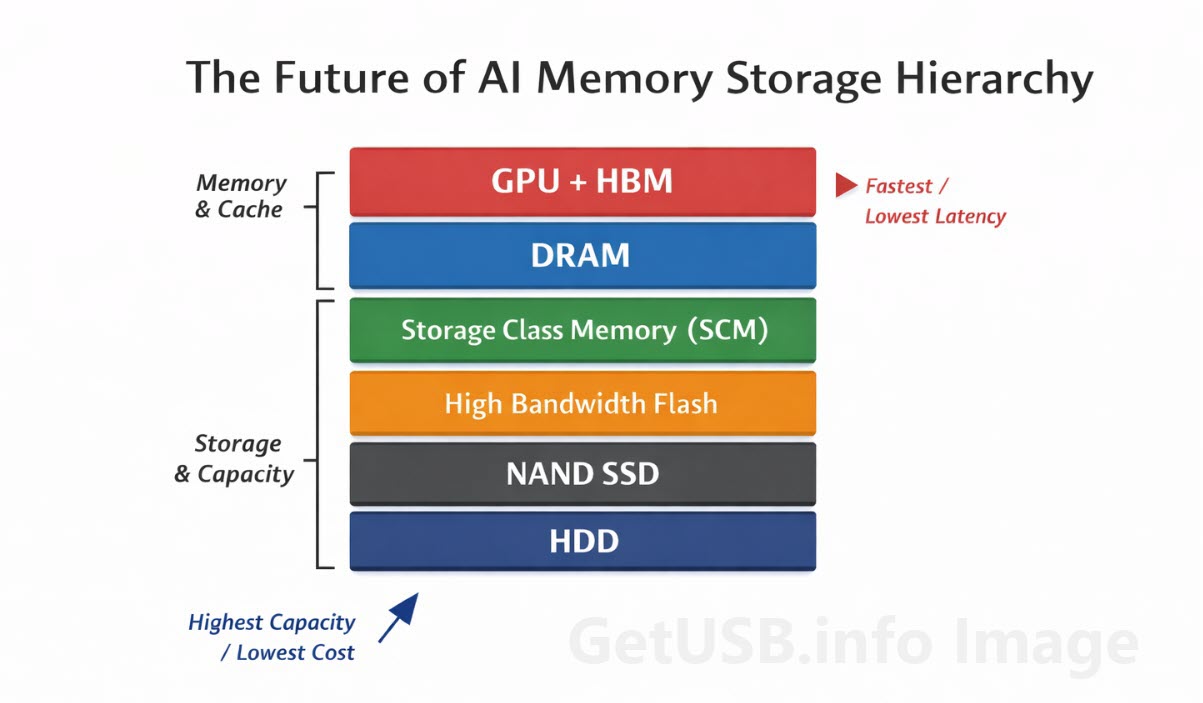
Genau hier kommt der Begriff „Memory Stack“ ins Spiel. Nicht als Marketing-Begriff, sondern als praktische Beschreibung dessen, was tatsächlich implementiert wird. Statt Storage und Memory strikt zu trennen, beginnen KI-Systeme, diese Grenze aufzuweichen und mehrere Ebenen zu schaffen, die sich je nach Geschwindigkeit, Kosten und Nähe zum Prozessor unterschiedlich verhalten.
NAND bleibt ein wichtiger Bestandteil dieses Stacks, insbesondere für Kapazität, steht aber inzwischen neben anderen Technologien, die speziell dafür entwickelt wurden, Workloads zu bedienen, bei denen Latenz und Bandbreite wichtiger sind als reines Speichervolumen.
Was rund um NAND aufgebaut wird
Betrachtet man das System aus dieser Perspektive, werden die Veränderungen nachvollziehbarer. Anstatt NAND alles erledigen zu lassen, führt die Branche zusätzliche Ebenen ein, die jeweils ein spezifisches Problem lösen. Einige davon sind bereits im Einsatz, andere befinden sich noch in der Entwicklung – gemeinsam bilden sie jedoch die Struktur, auf die moderne KI-Server zunehmend angewiesen sind.
In den kommenden Artikeln gehen wir auf jede dieser Ebenen detaillierter ein, denn jede verdient mehr Raum, als ein einzelner Überblicksartikel bieten kann. Für den Moment geht es darum, das Gesamtbild zu verstehen und zu sehen, wie die einzelnen Komponenten zusammenspielen.
High Bandwidth Memory (HBM)
Ganz oben im Stack, direkt in Nähe der GPU, befindet sich High Bandwidth Memory, kurz HBM. Dabei handelt es sich um gestapelten DRAM, der physisch nahe am Prozessor sitzt und extrem hohe Datenraten bei sehr niedriger Latenz ermöglicht. Es ist kein klassisches Storage-Medium, sondern eine spezialisierte Form von Speicher, die speziell dafür entwickelt wurde, GPUs kontinuierlich mit Daten zu versorgen.
Bei HBM geht es nicht um Kapazität, sondern darum, die GPU auszulasten – oft die teuerste Komponente im gesamten System. Wenn der Prozessor auf Daten warten muss, wird das gesamte System ineffizient. HBM priorisiert daher Bandbreite und Nähe zum Prozessor statt Größe.
In der Lagerhaus-Analogie ist HBM wie die nächste Palette, die bereits direkt am Verladebereich bereitsteht – ausgepackt und sofort verfügbar. Man erhöht damit nicht den Gesamtbestand im Lager, sondern sorgt dafür, dass der Stapler nie warten muss.
Für einen tieferen Vergleich zwischen HBM und neuen Alternativen haben wir das hier ausführlich behandelt: HBM vs HBF: Why the Memory Hierarchy is Being Stretched
Storage Class Memory (SCM)
Direkt darunter befindet sich eine Kategorie, die vor wenigen Jahren praktisch noch nicht existierte: Storage, das sich wie Memory verhält.
Storage Class Memory, oder SCM, schließt die Lücke zwischen DRAM und NAND. Es ist nicht so schnell wie echter Speicher und nicht so dicht wie Flash, bietet aber einen sinnvollen Kompromiss für Workloads, die schnelleren Zugriff benötigen als NAND liefern kann – ohne die Kosten von DRAM in großem Maßstab tragen zu müssen.
In KI-Systemen fungiert diese Zwischenschicht als Puffer und nimmt Druck von NAND, insbesondere bei großen Arbeitsdatensätzen, die nicht vollständig in den klassischen Speicher passen.
In der Lagerhaus-Analogie ist SCM der Zwischenbereich zwischen Regalen und Verladestation. Das Lager enthält alles, ist aber zu langsam für ständiges Hin- und Herlaufen. Der Verladebereich ist schnell, aber begrenzt. SCM ist die Zone dazwischen, in der die nächsten Lieferungen vorbereitet werden, damit alles reibungslos weiterläuft.
High Bandwidth Flash
Hier wird es besonders interessant, denn statt eine komplett neue Speicherart einzuführen, versucht die Branche auch, NAND selbst weiterzuentwickeln.
High Bandwidth Flash ist der Versuch, Flash weniger wie klassischen Storage und mehr wie eine Erweiterung von Memory zu behandeln. Ziel ist es nicht, NAND zu ersetzen, sondern dessen Integration und Zugriff so zu verändern, dass Daten effizienter an höhere Ebenen geliefert werden.
In gewisser Weise passt sich NAND hier an die neue Umgebung an, statt verdrängt zu werden – ein Muster, das wir in der Vergangenheit schon oft gesehen haben. Technologien verschwinden selten abrupt, sie entwickeln sich weiter.
DRAM und seine Grenzen
DRAM bleibt ein zentraler Bestandteil des gesamten Systems und wird ebenfalls nicht verschwinden. Es ist weiterhin der Hauptarbeitsspeicher für die meisten Systeme, einschließlich KI-Servern, und verarbeitet einen Großteil der aktiven Daten.
Gleichzeitig lässt sich DRAM nicht unbegrenzt skalieren. Kosten, Energieverbrauch und physische Grenzen spielen eine Rolle – besonders bei großen Systemen. Deshalb kann DRAM allein die steigenden Anforderungen durch KI nicht abfangen, was den Bedarf an zusätzlichen Schichten erklärt.
In der Lagerhaus-Analogie ist DRAM der eigentliche Verladebereich. Hier passiert die Arbeit – Kisten werden geöffnet, sortiert und weitergeleitet. Doch der Platz ist begrenzt. Irgendwann werden zusätzliche Zonen nötig, weil es ineffizient und teuer wäre, alles ausschließlich dort abzuwickeln.
Die stille Rückkehr der Festplatten
Trotz des Fokus auf schnelle Speichertechnologien bleiben klassische Festplatten ein Teil des Systems – insbesondere im unteren Bereich des Stacks, wo Kosten pro Terabyte wichtiger sind als Geschwindigkeit.
KI-Systeme erzeugen und verarbeiten enorme Datenmengen, und nicht alles muss im Hochleistungsspeicher liegen. Trainingsdaten, Archive und selten genutzte Informationen brauchen ebenfalls Platz – und dafür sind Festplatten nach wie vor eine der günstigsten Optionen.
Sie konkurrieren nicht mit NAND oder DRAM in Sachen Geschwindigkeit, entlasten diese aber erheblich, indem sie große Datenmengen aufnehmen.
Compute näher an den Storage bringen
Ein weiterer Trend besteht darin, die Distanz zwischen Daten und Verarbeitung zu reduzieren. Statt ständig große Datenmengen zwischen Storage und Compute hin- und herzuschieben, verlagern einige Architekturen Rechenoperationen näher an den Ort, an dem die Daten liegen.
Dieser Ansatz ersetzt schnelle Speicher nicht, verändert aber die Balance. Wenn bestimmte Aufgaben näher an den Daten ausgeführt werden, lassen sich Engpässe reduzieren und die Effizienz steigern.
Die Rolle des KI-Kontexts (KV Cache)
Ein oft unterschätzter Faktor ist die Menge an temporären Daten, die KI-Modelle während ihrer Ausführung erzeugen. Diese werden häufig als Kontext oder KV-Cache bezeichnet und stellen den aktuellen Arbeitszustand eines Modells dar.
Diese Daten passen nicht immer sauber in klassische Speicherstrukturen – vor allem im großen Maßstab. Deshalb beginnen Systeme, Storage als Erweiterung von Memory zu behandeln. Die Grenze zwischen beiden verschwimmt zunehmend.
In der Lagerhaus-Analogie entspricht der KV-Cache einer aktiven Arbeitsliste oder einem laufenden Protokoll. Es ist nicht das gesamte Inventar, aber entscheidend für den aktuellen Ablauf. Wird dieser Bereich zu groß oder unübersichtlich, gerät der gesamte Prozess ins Stocken.
Der neue KI-Memory-Stack
Betrachtet man das System als Ganzes, ähnelt es eher einer gestaffelten Struktur als einer klassischen Hierarchie.
Ganz oben steht die GPU mit HBM für unmittelbare Hochgeschwindigkeitsverarbeitung. Dahinter folgt DRAM für aktive Workloads. Darunter sorgen SCM und High Bandwidth Flash für zusätzliche Kapazität bei akzeptabler Performance.
Weiter unten übernimmt NAND die großflächige Datenspeicherung, während Festplatten für kostengünstige Langzeitarchive zuständig sind.
In der Lagerhaus-Analogie ergibt sich ein klares Bild: HBM ist die Palette am Dock, DRAM die Arbeitsfläche, SCM die Zwischenzone, NAND die Regale und Festplatten das hintere Lager. Das System funktioniert, weil jede Ebene eine klare Aufgabe hat.
Jede Schicht erfüllt ihren Zweck, und zusammen bilden sie ein System, das den Anforderungen moderner KI deutlich besser gerecht wird als jede einzelne Technologie für sich allein.
Was das für die Zukunft bedeutet
Die wichtigste Erkenntnis ist nicht, dass NAND ersetzt wird oder eine neue Technologie seinen Platz einnimmt. Was passiert, ist deutlich schrittweiser – und ehrlich gesagt auch interessanter.
Die Branche erkennt, dass keine einzelne Ebene alles leisten kann, insbesondere unter den Anforderungen von KI. Statt eine Technologie zu überdehnen, wird ein System geschaffen, in dem mehrere Ebenen zusammenarbeiten.
Das verändert die Art, wie wir über Storage denken. Es geht nicht mehr nur um Kapazität oder Geschwindigkeit, sondern darum, wie Daten durch das System fließen und wie effizient jede Ebene die nächste unterstützt.
Und während sich diese Architekturen weiterentwickeln, bleibt NAND ein zentraler Bestandteil – nur eben nicht mehr der einzige.
Tags:HBM, KI-Infrastruktur, KI-Memory-Stack, NAND-Flash, Storage Class Memory