KI-Systeme verlangsamen sich in der Regel nicht wegen mangelnder Rechenleistung, sondern weil das System Daten nicht schnell genug bewegen kann, um den Prozessor konstant mit Informationen zu versorgen.
Mit anderen Worten: Der Engpass liegt nicht in der Fähigkeit, Daten zu verarbeiten, sondern darin, diese Daten mit der Geschwindigkeit bereitzustellen, die moderne KI-Workloads erfordern.
Genau hier wird High Bandwidth Memory (HBM) zu einem wichtigen Bestandteil der Architektur.
Für einen umfassenderen Blick darauf, wie sich Speicher über Flash hinaus entwickelt und warum KI-Systeme heute auf mehrere Ebenen angewiesen sind, siehe unsere Hauptanalyse: NAND wird nicht verschwinden, aber KI-Server sind inzwischen auf mehr als nur Flash angewiesen.
Was ist High Bandwidth Memory (HBM)?
High Bandwidth Memory ist eine Form von gestapeltem DRAM, die extrem nah am Prozessor platziert wird, oft nur wenige Millimeter vom GPU-Die entfernt, um die physische Distanz zu minimieren, die Daten zurücklegen müssen.
Im Gegensatz zu herkömmlichem Systemspeicher, der auf längere elektrische Wege und schmalere Datenkanäle angewiesen ist, basiert HBM auf Nähe und Parallelität, wodurch deutlich mehr Daten gleichzeitig und mit wesentlich geringerer Verzögerung bewegt werden können.
- Breite Speicherbusse, oft tausende Bits breit
- Extrem kurze Verbindungswege zwischen Speicher und Prozessor
- Massiv paralleler Zugriff auf Daten
Das Ziel ist einfach: die Distanz zwischen Datenspeicherung und Verarbeitung zu reduzieren, denn in Hochleistungssystemen summieren sich selbst kleine Verzögerungen sehr schnell.
In der Praxis bedeutet Distanz direkt höhere Latenz, und genau diese Latenz gehört zu den Hauptfaktoren, die die Leistung von KI-Systemen begrenzen.
Eine einfache Vorstellung von HBM
Ein hilfreiches Bild ist ein klassisches System als Fabrik, die über eine Autobahn mit einem Lager verbunden ist.
Jedes Mal, wenn die Fabrik Teile benötigt, müssen diese hin- und hertransportiert werden, was Verzögerungen verursacht, den Energieverbrauch erhöht und die Geschwindigkeit des gesamten Systems begrenzt.
HBM verändert diese Beziehung, indem das Lager im Grunde direkt auf die Fabrikhalle gestapelt wird.
Anstatt auf Transport angewiesen zu sein, ist alles sofort verfügbar, wodurch die Verzögerungen, die durch längere Wege entstehen, praktisch verschwinden.
Genau das macht HBM für eine GPU: Der Speicher wird so nah an die Recheneinheit gebracht, dass die Datenbewegung im Vergleich zu klassischen Designs nahezu sofort erfolgt.
Wie HBM physisch aufgebaut ist
Der Vorteil von HBM liegt nicht nur im Layout, sondern auch darin, wie der Speicher auf Siliziumebene konstruiert ist.
HBM wird aufgebaut, indem mehrere DRAM-Dies vertikal gestapelt und mit sogenannten Through-Silicon Vias (TSVs) verbunden werden, also mikroskopisch kleinen vertikalen Leitungen, die direkt durch das Silizium geführt werden und elektrische Verbindungen zwischen den Schichten ermöglichen.
Diese gestapelten Speichermodule werden anschließend zusammen mit der GPU auf einem Interposer montiert, wodurch ein eng integriertes Paket entsteht, bei dem Speicher und Recheneinheit als ein gemeinsames System arbeiten, statt als getrennte Komponenten.
Das Ergebnis ist eine Kombination aus extrem breiten Datenpfaden und sehr kurzen elektrischen Wegen, die zusammen die hohe Bandbreite ermöglichen, die HBM auszeichnet.
Warum KI auf HBM angewiesen ist
KI-Workloads, insbesondere beim Training von Modellen, erfordern eine kontinuierliche Bewegung großer Datenmengen, oft mit Milliarden oder sogar Billionen von Parametern, die ständig gelesen, aktualisiert und neu geschrieben werden müssen.
Dadurch entsteht gleichzeitig ein Bedarf an hoher Bandbreite, um große Datenmengen schnell zu bewegen, und niedriger Latenz, damit die Recheneinheiten nicht untätig auf Daten warten müssen.
- Hohe Bandbreite sorgt dafür, dass große Datenmengen schnell übertragen werden können
- Niedrige Latenz stellt sicher, dass die Recheneinheiten optimal ausgelastet bleiben
Traditionelle Speicherarchitekturen haben Schwierigkeiten, beide Anforderungen gleichzeitig zu erfüllen, weshalb HBM zu einem Standardbaustein in modernen High-End-KI-Beschleunigern geworden ist.
Ohne HBM würde selbst die leistungsstärkste GPU einen erheblichen Teil ihrer Zeit damit verbringen, auf Daten zu warten, anstatt sie zu verarbeiten.
Der Kompromiss: Geschwindigkeit vs. Kosten
So leistungsfähig HBM auch ist, bringt es durch sein gestapeltes Design und die aufwendige Verpackungstechnologie zusätzliche Komplexität und höhere Kosten mit sich.
Die Kombination aus mehreren DRAM-Schichten, präzisen Verbindungsstrukturen und Interposer-Integration macht HBM zu einer der teuersten aktuell verfügbaren Speichertechnologien.
Deshalb wird HBM in der Regel dort eingesetzt, wo maximale Leistung entscheidend ist und die Kosten gerechtfertigt werden können, etwa beim KI-Training oder in High-Performance-Computing-Umgebungen.
Allgemeine Systeme, bei denen Kosten eine größere Rolle spielen, setzen weiterhin auf konventionellere Speicherlösungen.
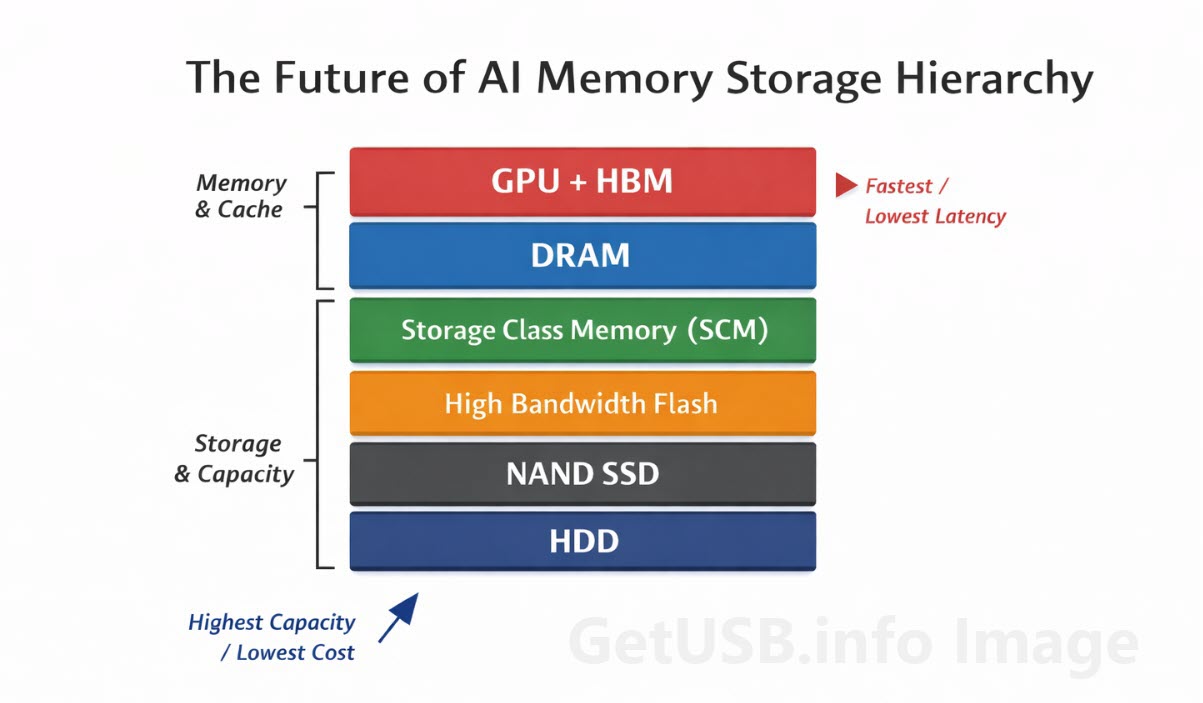
Wo HBM ins Gesamtbild passt
HBM ersetzt andere Speicherarten nicht, sondern befindet sich an der Spitze einer mehrstufigen Speicherhierarchie, in der jede Ebene für ein bestimmtes Verhältnis aus Geschwindigkeit, Kosten und Kapazität optimiert ist.
| Technologie | Typische Latenz | Bandbreite | Kosten pro GB | Hauptrolle |
|---|---|---|---|---|
| HBM (gestapelter DRAM) | Nanosekunden | Terabyte/s | Sehr hoch | KI-Trainingsspeicher |
| DDR DRAM | ~100ns | Hoch | Hoch | Arbeitsspeicher |
| NVMe SSD | Mikrosekunden–Millisekunden | Moderat | Niedrig | Massenspeicher |
Jede Ebene existiert aufgrund der Kompromisse zwischen Leistung, Kosten und Kapazität, denn keine einzelne Technologie kann alle drei Faktoren gleichzeitig optimieren.
HBM befindet sich in der obersten Leistungsklasse, in der Geschwindigkeit Vorrang vor Kosten hat, und ist damit essenziell für Workloads, die keine Verzögerungen tolerieren können.
Der Wandel
HBM sollte nicht einfach als schnellerer Speicher betrachtet werden, sondern als ein grundlegender Wandel im Systemdesign, bei dem Speicher physisch näher an die Recheneinheit rückt, um einen der größten Engpässe moderner Computerarchitekturen zu beseitigen.
In KI-Systemen, bei denen die Leistung direkt davon abhängt, wie schnell Daten verfügbar sind und verarbeitet werden können, spielt diese Veränderung eine entscheidende Rolle.
Letztlich sind selbst die fortschrittlichsten Prozessoren auf einen konstanten Datenfluss angewiesen, und genau dieser verbesserte Datenfluss macht Technologien wie HBM so wichtig.
Redaktioneller Hinweis und Bildinformation: Dieser Artikel wurde von GetUSB.info auf Grundlage unserer redaktionellen Recherche und unseres technischen Verständnisses von Speicherarchitekturen und Hardware entwickelt und überprüft.
Bildhinweis: Das verwendete Bild basiert auf einer realen Chipaufnahme und wurde zur besseren Veranschaulichung des HBM-Konzepts visuell angepasst. Die Darstellung dient ausschließlich der Erklärung und ist als interpretative Grafik zu verstehen, nicht als exakte Referenz eines Herstellungsprozesses.
Wie dieser Artikel erstellt wurde: GetUSB.info hat Themenrichtung, technischen Ansatz und finale redaktionelle Prüfung bereitgestellt. KI-Tools wurden zur Unterstützung von Struktur und Lesefluss eingesetzt, wobei die Inhalte durchgehend menschlich überprüft wurden.