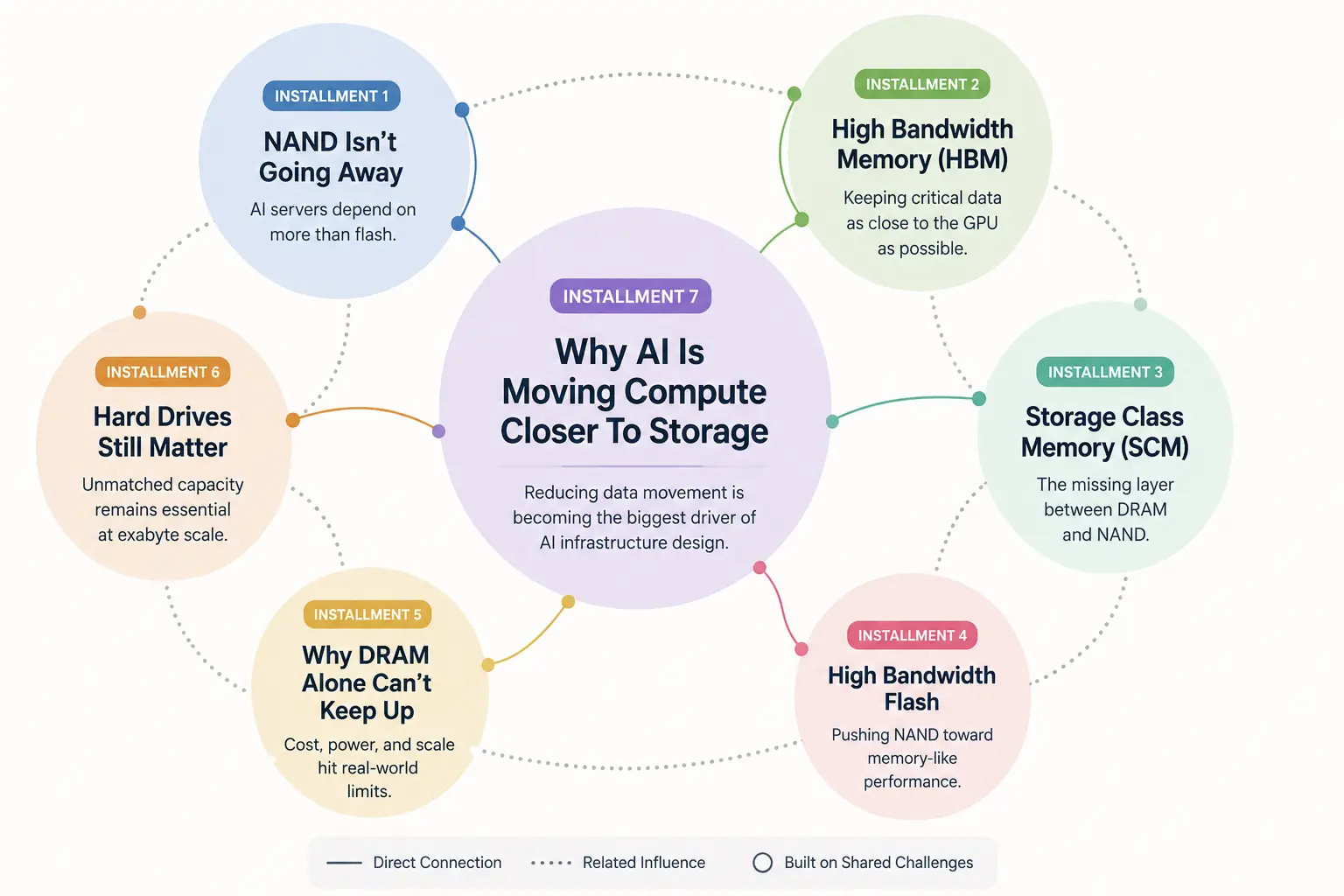
Wenn Sie die früheren Beiträge dieser Serie verfolgt haben, ist Ihnen wahrscheinlich bereits ein Muster aufgefallen.
Im ersten Artikel ging es darum, dass NAND-Flash nicht verschwindet, sondern Teil einer deutlich größeren KI-Speicherhierarchie wird. Danach haben wir uns High Bandwidth Memory (HBM) angesehen und warum moderne GPUs darauf angewiesen sind, Daten physisch näher am Prozessor zu haben. Anschließend ging es um Storage Class Memory, High Bandwidth Flash, die Grenzen der DRAM-Skalierung und schließlich darum, warum selbst klassische Festplatten weiterhin wichtig bleiben, weil KI-Infrastruktur in einer Größenordnung arbeitet, die viele Menschen deutlich unterschätzen.
Auf den ersten Blick wirken diese Themen vielleicht wie getrennte Baustellen.
Das sind sie aber nicht.
Sie sind alle Symptome desselben grundlegenden Drucks: KI-Systeme kämpfen nicht mehr in erster Linie mit Rechenleistung. Sie kämpfen damit, wie effizient sie Daten bewegen können.
Diese Veränderung stellt fast alles auf den Kopf, was die Architektur moderner Infrastruktur betrifft.
Über Jahrzehnte folgte Computing einem recht stabilen Modell. Storage hielt die Daten, Arbeitsspeicher stellte sie bereit, und Prozessoren holten sich, was sie brauchten. Wenn Prozessoren schneller wurden, versuchte das System einfach, sie effizienter zu versorgen: mit besseren Bussen, größeren Caches und schnelleren Speichertechnologien.
KI hat die Größenordnung des Problems verändert.
Moderne GPU-Cluster können Informationen in einem so enormen Tempo verarbeiten, dass das Bewegen von Daten durch das System selbst zu einem der größten Engpässe der gesamten Architektur geworden ist. In manchen Umgebungen ist der Prozessor selbst nicht mehr der langsame Teil. Die Verzögerung entsteht dadurch, dass die richtigen Daten nicht schnell und gleichmäßig genug beim Prozessor ankommen, um ihn vollständig auszulasten.
Diese Erkenntnis zwingt die Branche leise, aber deutlich in eine neue Richtung.
Statt immer größere Datenmengen ständig im System hin und her zu bewegen, beginnt KI-Infrastruktur damit, Teile der Verarbeitung näher dorthin zu verlagern, wo die Daten bereits liegen.
Und wenn man versteht, warum das passiert, passen viele der früheren Artikel dieser Serie plötzlich viel klarer zusammen.
KI stößt zunehmend an eine Wand der Datenbewegung
Eine der wichtigsten Ideen aus dem früheren HBM-Artikel war, dass moderne KI-Systeme oft nicht deshalb langsamer werden, weil dem Prozessor Rechenleistung fehlt, sondern weil das System die Daten nicht schnell genug liefern kann, um den Prozessor beschäftigt zu halten.
Dieses Problem wird deutlich ernster, sobald KI-Workloads über ganze Racks und Cluster hinweg skalieren.
Ein moderner KI-Beschleuniger kann erstaunliche Mengen an Informationen parallel verarbeiten. Das Problem ist, dass Datensätze nicht mehr klein genug sind, um vollständig in den schnellsten Speicherebenen zu liegen. Selbst mit HBM und großen DRAM-Pools müssen enorme Datenmengen weiterhin über Interconnects, Busse, Fabrics, Storage-Schichten und Netzwerkinfrastruktur transportiert werden.
Diese Bewegung hat ihren Preis.
Sie zeigt sich als Latenz, aber das ist nur ein Teil der Geschichte. Sie zeigt sich auch als Stromverbrauch, Wärme, Kühlbedarf, Überlastung, Synchronisationsverzögerungen und ungenutzte Rechenzyklen. Wie wir im DRAM-Beitrag besprochen haben, können selbst winzige Verzögerungen überraschend teuer werden, sobald Tausende GPUs gleichzeitig arbeiten. Eine kleine Pause, multipliziert über einen großen KI-Cluster, kann eine enorme Menge verlorener Auslastung bedeuten.
Das verändert die technischen Prioritäten.
Über viele Jahre wurde Infrastruktur hauptsächlich darauf ausgelegt, die Rechenleistung zu maximieren. KI-Systeme zwingen Ingenieure nun dazu, genauso stark über Datenlokalität nachzudenken, also darüber, wo Informationen physisch im Verhältnis zu dem Prozessor liegen, der sie verwenden möchte.
Einfach gesagt: Entfernung zählt heute deutlich mehr als früher.
GPUs wurden so schnell, dass der Rest des Systems zurückfiel
Eine der merkwürdigen Eigenschaften von KI-Infrastruktur ist, dass Fortschritt in einem Bereich sehr oft Schwächen an anderer Stelle sichtbar macht.
Als GPUs schneller wurden, wurde die Speicherbandbreite zum Engpass. Das führte zu HBM. Als die Kapazitätsgrenzen von HBM deutlicher wurden, begann die Branche mit Zwischenschichten wie Storage Class Memory zu arbeiten. Als DRAM-Skalierung teuer und physisch schwieriger wurde, stützten sich Systeme stärker auf NAND und untersuchten gleichzeitig Konzepte wie High Bandwidth Flash.
Und als KI-Datensätze weiter in den Peta- und Exabyte-Bereich wuchsen, blieben Festplatten im Hintergrund unverzichtbar, weil die Wirtschaftlichkeit beim Speichern solcher Datenmengen anders kaum funktionieren kann.
Jeder Artikel dieser Serie hat im Grunde aus einem anderen Blickwinkel auf dieselbe Schlussfolgerung hingewiesen.
Die alte Annahme, dass Compute hier sitzt und Storage dort drüben, beginnt aufzubrechen. Der Grund ist ziemlich einfach: GPUs können Daten inzwischen schneller verarbeiten, als klassische Architekturen sie bequem liefern können.
Dadurch entsteht eine Situation, in der enorme Teile der Systemaktivität nur noch damit beschäftigt sind, Informationen von einem Ort zum anderen zu transportieren. Praktisch gesehen sehen manche KI-Umgebungen inzwischen weniger wie reine Rechenprobleme aus und mehr wie Logistikprobleme.
Die Branche begann, eine andere Frage zu stellen
Lange Zeit konzentrierte sich Storage-Innovation vor allem darauf, Speichermedien schneller zu machen. Schnellere SSDs, schnellere Schnittstellen, schnellerer NAND und schnellere Controller waren wichtig, und sie sind es auch heute noch.
Aber KI-Workloads legten ein tieferes Problem unter all dem offen.
Irgendwann erkannten Ingenieure, dass das Problem nicht immer die Geschwindigkeit des Speichermediums selbst war. Das Problem war die wiederholte Bewegung riesiger Datenmengen quer durch das gesamte System.
Diese feine Unterscheidung ist wichtig, denn sobald das Problem Datenbewegung statt einfacher Speichergeschwindigkeit ist, verändert sich auch die Lösung.
Statt endlos zu fragen, wie Storage schneller gemacht werden kann, begann die Branche zu fragen, wie weit die Daten überhaupt reisen müssen.
Diese Frage beeinflusst inzwischen nahezu jeden Bereich moderner KI-Infrastruktur.
Compute rückt näher an den Ort, an dem die Daten bereits liegen
Hier beginnt sich die Architektur zu verschieben.
Statt Storage als vollständig passive Schicht zu behandeln, die einfach auf Anfragen wartet, beginnen neuere Systeme damit, bestimmte Aufgaben näher an den Daten selbst auszuführen. Nicht unbedingt vollständige GPU-Verarbeitung, aber lokale Operationen, die unnötige Bewegung durch den Rest des Systems reduzieren.
Manche Systeme führen heute Filterung, Indexierung, Suchvorgänge, Kompression, Vorbereitung für Retrieval und Datenorganisation näher an der Storage-Schicht aus, bevor die Informationen überhaupt die primären Recheneinheiten erreichen.
Das Ziel ist nicht, GPUs abzuschaffen oder schnellen Arbeitsspeicher zu ersetzen. Das Ziel ist, Verschwendung zu reduzieren.
Wenn das System vermeiden kann, enorme Mengen unnötiger Daten durch die Infrastruktur zu transportieren, wird die gesamte Plattform effizienter. Das ist einer der Gründe, warum die Grenze zwischen Compute und Storage zunehmend verschwimmt.
Storage verhält sich nicht mehr wie ein komplett inaktives Ziel am unteren Ende der Hierarchie. Es wird stärker daran beteiligt, wie Daten vorbereitet, bereitgestellt, gefiltert und nach oben geliefert werden.
Wenn Sie an den früheren Artikel über High Bandwidth Flash zurückdenken, ergibt diese Richtung viel Sinn. Dieser Artikel zeigte, wie NAND selbst in Richtung eines speicherähnlicheren Verhaltens gedrückt wurde. Dieser Beitrag geht denselben Gedanken einen Schritt weiter und zeigt, wie sich auch die umgebende Architektur an die Kosten der Datenbewegung anpasst.
Die Lagerhaus-Analogie sieht plötzlich anders aus
Die Lagerhaus-Analogie, die wir in dieser Serie verwendet haben, funktioniert auch hier noch, aber das Lagerhaus selbst hat sich weiterentwickelt, weil sich die Arbeit darin verändert hat.
In den früheren Beiträgen war die Aufteilung ziemlich klar. HBM war die Laderampe, an der die nächste Palette schon direkt neben den Arbeitern bereitstand. DRAM war die aktive Arbeitsfläche, auf der gerade sortiert und verarbeitet wurde. Storage Class Memory wurde zum Zwischenbereich direkt hinter der Rampe, während NAND die eigentlichen Lagerregale weiter hinten darstellte. Festplatten übernahmen den tieferen Massenspeicher, wo langfristiger Bestand lag, weil Kapazität wichtiger war als sofortiger Zugriff.
Dieses Modell hält grundsätzlich noch zusammen, aber KI-Systeme zeigen zunehmend, wie ineffizient die Bewegung zwischen diesen Bereichen werden kann.
Stellen Sie sich ein Lager vor, in dem die Arbeiter mehr Zeit damit verbringen, mit Gabelstaplern quer durch das Gebäude zu fahren, als tatsächlich Waren zu verarbeiten. Zuerst reagiert die Leitung, indem sie schnellere Gabelstapler kauft, die Gänge verbreitert und die Laderampen verbessert. Diese Maßnahmen helfen eine Zeit lang, aber irgendwann erreicht der Betrieb einen Punkt, an dem der Transport selbst zum Problem wird. Die Verzögerungen entstehen nicht mehr durch langsame Arbeiter oder schlechte Ausrüstung. Die Verzögerungen entstehen durch die schiere Menge an Bewegung, die nötig ist, um den Ablauf am Laufen zu halten.
Genau darauf laufen große KI-Systeme zunehmend hinaus.
Es geht nicht mehr nur darum, wie schnell Daten verarbeitet werden können, sobald sie die GPU erreichen. Es geht darum, wie viel Aufwand die Infrastruktur immer wieder betreiben muss, um diese Daten überhaupt durch das System zu transportieren.
Statt also den Transport endlos weiter zu optimieren, beginnt sich die Anordnung zu verändern. Kleine Arbeitsstationen tauchen näher an den Regalen selbst auf. Bestimmte Sortieraufgaben passieren lokal. Filterung passiert lokal. Datenvorbereitung beginnt näher an dem Ort, an dem die Informationen bereits liegen, wodurch das System seltener riesige Materialmengen durch den gesamten Betrieb bewegen muss.
Genau diese Verschiebung beginnt KI-Infrastruktur auf architektonischer Ebene zu vollziehen. Das Ziel ist nicht, Storage in einen Prozessor zu verwandeln oder zentrale Rechenleistung vollständig abzuschaffen. Das Ziel ist, unnötige Bewegung zu reduzieren, weil bei KI-Skalierung selbst kleine Ineffizienzen überraschend teuer werden, sobald sie über Tausende gleichzeitig arbeitende Beschleuniger multipliziert werden.
KI-Infrastruktur wird aus Notwendigkeit stärker verteilt
Eine der interessanteren Folgen dieser Entwicklung ist, dass KI-Infrastruktur deutlich verteilter wird, als klassische Computerumgebungen es je sein mussten.
Ältere Architekturen gingen davon aus, dass die wichtigste Arbeit an zentralen Rechenorten stattfindet, während Storage weitgehend passiv und von der Verarbeitungsschicht getrennt bleibt. Dieses Modell funktionierte über Jahrzehnte recht gut, weil die Datenmenge, die durch das System floss, im Verhältnis zur Geschwindigkeit der Prozessoren noch beherrschbar war.
KI verändert die Größenordnung dieser Gleichung vollständig.
Die Menge an Informationen, die verarbeitet, erneut aufgerufen, bereitgestellt, zwischengespeichert, indexiert und abgerufen wird, ist inzwischen so groß, dass zentrale Bewegung selbst Ineffizienzen erzeugt. Statt dass Compute einfach nach unten in den Storage greift, wenn etwas benötigt wird, versuchen Systeme zunehmend, nützliche Daten näher dort zu halten, wo sie wahrscheinlich als Nächstes gebraucht werden.
Das ist einer der Gründe, warum Technologien wie Vektordatenbanken, verteilte Inferenzsysteme, Retrieval-Schichten, lokales Caching und Near-Data Processing so viel Aufmerksamkeit bekommen. An der Oberfläche wirken diese Themen vielleicht wie getrennte Technologien, die unterschiedliche Probleme lösen. Darunter reagieren sie aber alle auf denselben Druck. Die Branche versucht zu reduzieren, wie oft enorme Informationsmengen lange Wege durch die Infrastruktur zurücklegen müssen, bevor sinnvolle Arbeit überhaupt beginnen kann.
Wie Sie wahrscheinlich im Verlauf dieser Serie bemerkt haben, wird die Speicherhierarchie selbst allmählich weniger starr. Die saubere Trennung zwischen „Compute hier“ und „Storage dort“ beginnt weicher zu werden, weil KI-Workloads Systeme belohnen, die Daten physisch näher an dem Ort halten, an dem Verarbeitung stattfindet.
Dieser Trend wird sich wahrscheinlich fortsetzen, weil die Wirtschaftlichkeit großer KI-Systeme Effizienz bei der Bewegung inzwischen fast genauso stark belohnt wie rohe Rechenleistung.
Die Speicherhierarchie beginnt zu verschwimmen
Eines der stilleren Themen, das sich durch jeden Beitrag dieser Serie zieht, ist das allmähliche Auflösen der alten Grenzen zwischen Arbeitsspeicher, Storage und Compute.
Im HBM-Artikel haben wir betrachtet, wie Speicher physisch näher an den Prozessor selbst gerückt wurde, weil sogar die klassische Platzierung von DRAM bei KI-Skalierung ausreichend große Verzögerungen verursachte. Im Beitrag zu Storage Class Memory verlagerte sich der Fokus darauf, den harten Übergang zwischen schnellem Arbeitsspeicher und langsamerem persistentem Storage zu reduzieren. High Bandwidth Flash drückte NAND in eine aktivere Rolle innerhalb des Arbeitsdatenpfads, während der DRAM-Artikel zeigte, warum einfaches Hochskalieren von traditionellem Arbeitsspeicher auf Dauer sowohl wirtschaftlich als auch physikalisch schwierig wird.
Dieser Artikel führt dieselbe Entwicklung nun einen Schritt weiter, indem er zeigt, wie sich die Architektur selbst an die Kosten der Datenbewegung anpasst.
Besonders interessant ist, dass keine dieser Technologien die anderen wirklich ersetzt. Die Branche hat NAND nicht aufgegeben, als HBM aufkam. Sie hat DRAM nicht ersetzt, nur weil Storage Class Memory auftauchte. Auch Festplatten bleiben tief relevant, trotz jahrzehntelanger Vorhersagen, dass Solid-State-Speicher sie vollständig verdrängen würden.
Stattdessen wird das System stärker geschichtet, stärker spezialisiert und bewusster darin, wo Daten physisch im Verhältnis zu den Rechenressourcen liegen, die sie nutzen wollen.
Diese Unterscheidung ist wichtig, weil sie verändert, wie wir über die Zukunft der KI-Infrastruktur denken sollten. Die Entwicklung passiert nicht, weil eine einzelne Durchbruchstechnologie plötzlich alles gelöst hat. Sie passiert, weil der Workload selbst die Branche gezwungen hat, neu zu organisieren, wie jede Ebene Informationen effizient an die Compute-Seite liefert.
Wenn man einen Schritt zurücktritt und das größere Bild betrachtet, wird das Muster deutlich leichter erkennbar. Jede größere Verschiebung, die wir in dieser Serie besprochen haben, weist letztlich auf dasselbe Ziel hin: weniger Zeit, Energie und Infrastrukturaufwand dafür aufzuwenden, Informationen einfach nur von einem Ort zum anderen zu bewegen.
Die Zukunft hängt vielleicht stärker von Datenplatzierung ab als von roher Rechenleistung
Sehr lange hat die Technologiebranche Fortschritt vor allem über rohe Rechenleistung gemessen. Schnellere Prozessoren, größere Beschleuniger, mehr Kerne und mehr Parallelität galten als zentrale Zeichen des Fortschritts, weil bei den meisten klassischen Workloads eine bessere Rechenleistung normalerweise das Gesamtsystem verbesserte.
KI zwingt zu einer differenzierteren Diskussion.
Sobald Prozessoren schnell genug werden, besteht die größere Herausforderung nicht mehr darin, Operationen auszuführen. Sie besteht darin, diese Prozessoren konstant genug mit nützlichen Daten zu versorgen, damit teure Leerlaufzeiten vermieden werden. Diese feine Veränderung beeinflusst heute nahezu jede größere Architekturentscheidung in moderner KI-Infrastruktur.
Interessant ist, dass die Lösung nicht mehr einfach darin besteht, isoliert schnellere Speichermedien oder größere Speicherpools zu bauen. Stattdessen konzentriert sich die Branche zunehmend darauf, wo Daten im System liegen, wie oft sie bewegt werden und wie intelligent die Architektur unnötigen Transport minimieren kann, bevor Rechenressourcen überhaupt beteiligt werden.
Deshalb ist Nähe ein so wiederkehrendes Thema in jedem Artikel dieser Serie. HBM rückte Speicher physisch näher an die GPU. Storage Class Memory verringerte die Lücke zwischen Arbeitsspeicher und Storage. High Bandwidth Flash versuchte, NAND aktiver an der Speicherhierarchie teilnehmen zu lassen. Verteilte Storage-Systeme und Near-Data-Processing-Architekturen versuchen nun, die Bewegung durch die Infrastruktur selbst zu reduzieren.
All diese Entwicklungen reagieren auf dieselbe Erkenntnis.
Bei KI-Skalierung wird effiziente Datenbewegung fast so wichtig wie das Verarbeiten der Daten, sobald sie angekommen sind.
Und genau das könnte am Ende zu einer der prägenden Architekturveränderungen der gesamten KI-Ära werden.
KI-Speicherinfrastruktur-Serie
Dieser Artikel ist Teil unserer laufenden Serie darüber, wie KI-Infrastruktur die Beziehung zwischen Arbeitsspeicher, Storage und Compute verändert. Wenn Sie hier in die Diskussion einsteigen, liefern die früheren Beiträge die Grundlage dafür, warum diese Verschiebung überhaupt stattfindet.
Teil Eins:
NAND verschwindet nicht, aber KI-Server sind heute auf mehr als nur Flash angewiesen
Teil Zwei:
Was ist High Bandwidth Memory (HBM) und warum ist es für KI so wichtig?
Teil Drei:
Storage Class Memory erklärt: die fehlende Schicht zwischen DRAM und NAND
Teil Vier:
High Bandwidth Flash: Kann NAND endlich wie Arbeitsspeicher agieren?
Teil Fünf:
Warum DRAM allein mit KI nicht mehr Schritt halten kann
Teil Sechs:
Warum Festplatten für KI-Infrastruktur weiterhin kritisch sind
Teil Sieben:
Warum KI Compute näher an den Speicher heranrückt
Redaktioneller Hinweis: Dieser Artikel ist Teil der laufenden Serie über KI-Infrastruktur und Speicherarchitektur, die auf GetUSB.info veröffentlicht wird. Der Artikel wurde mit KI-gestützter redaktioneller Unterstützung für Struktur und Lesbarkeit recherchiert und geschrieben und anschließend vom GetUSB-Redaktionsteam auf technische Genauigkeit, inhaltliche Kontinuität und Klarheit geprüft und überarbeitet.
Über den Autor
Dieser Artikel wurde unter der Leitung von Matt LeBoff entwickelt, einem langjährigen Mitwirkenden bei GetUSB.info mit mehr als zwei Jahrzehnten Erfahrung in USB-Technologie, Flash-Speicherverhalten und Datenspeichersystemen. Die hier dargestellte Perspektive basiert auf praktischer Branchenerfahrung und laufender Analyse dazu, wie reale Systeme unter sich verändernden Workloads arbeiten, einschließlich KI-Infrastruktur.